
How is the video memory used, and why is this often the limiting factor in what models can be run?
Video memory or VRAM, is used to both store the active model weights and the KV cache of the current conversation. The required VRAM for a model depends on the number of parameters in the base model, and its quantization level.
Parameters
Think of a parameter as a single connection or "synapse" in the AI's digital brain. When the AI is being trained, it adjusts these billions of connections to learn how words relate to each other. Each parameter is represented by a large number, generally 16-bit float, taking up two bytes of storage or VRAM. An uncompressed 8 billion parameter or “8b” model will take about 16GB of space on the disk or loaded into memory.
Quantization
Quantization is lossy compression of an AI model's brain by reducing the precision of parameters. Quantization reduces the number of bits used to represent each number, shrinking the model so it fits on cheaper or consumer-grade GPUs. For example the 8b model with INT8 quantization takes up half the space. However this can reduce the precision of the model and may reduce the quality of the output.
| Format | Bits per Parameter | Memory per 1B Parameters | Quality |
|---|---|---|---|
| FP16 / BF16 | 16-bit | ~2 GB | Original (Lossless) |
| INT8 / Q8 | 8-bit | ~1 GB | Near-Perfect (99%+) |
| INT4 / Q4 | 4-bit | ~0.5 GB | Great (95-98%) |
| EXL2 / IQ3 | 2-3 bit | ~0.3 - 0.4 GB | Noticeable Loss |
Lossless Compression
IBM’s ZipNN open-source compression library provides lossless compression potentially reducing model download and storage size by as much as 33 percent, however this is unlikely to affect the VRAM used by a model. Lossless compression is achieved by replacing duplicate sequences with pointers to the original sequence. Many English speakers already do this, replacing longer words like “Hello” with shorter words like “Hi” which have the same meaning. The compression relies on some statistical research showing that most parameters share one of twelve exponents (out of 256 possible values) 99.9% of the time. ZipNN was introduced around mid-2025, while not yet widely used, it will likely be adopted to help reduce hosting costs and download times for larger models.
Estimating video RAM usage for a given model
With the above information, we can create a simple equation to approximate the VRAM used for a model. We start by multiplying the number of parameters ( in billions ) by the quantization bits (precision) and dividing by 8 to convert from bits to bytes. Finally we multiply by 1.2 to provide 40% for KVs and system overhead, the result is the bare minimum VRAM required to run a model. Most consumer video cards will support 6GB, 8GB, 12GB, 16GB, 20GB, 24GB, or 32GB of VRAM, with some “AI” Accelerators supporting up to 80GB VRAM, so we should round up to these values to ensure that the video card we have can run a model.
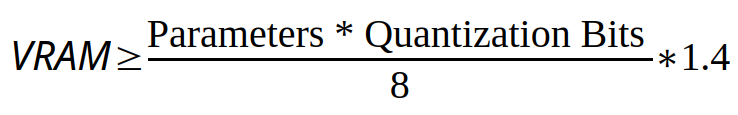
The number of parameters is normally included in the model name, however the bits per parameter or quantization are not for the base models, generally we can assume 16-bit unless otherwise stated. Refined models will most often include the quantization method in the model name. Some models will include recommended hardware and minimum VRAM, for those we recommend following the documented recommendation.
Parameter GPU Memory Requirements
| Model Size (Parameters) | Quantization | ||
|---|---|---|---|
| 16-bit (FP16) | 8-bit (INT8/FP8) | 4-bit (INT4/FP4) | |
| 3b to 4b | 8 GB to 12 GB | 4 GB to 6 GB | 4 GB |
| 7b to 8b | 16 GB to 24 GB | 8 GB to 12 GB | 6 GB to 8 GB |
| 10b to 13b | 24 GB to 32 GB | 12 GB to 24 GB | 6 GB to 12 GB |
| 30b to 34b | 60 GB to 80 GB | 32 GB to 48 GB | 16 GB to 24 GB |
| 70B | Multi-GPU 160 GB | 48 GB | 24 GB |
| Color Key | |||
| Mid-tier graphics cards | |||
| High-end gaming cards | |||
| "AI" accelerators | |||
| Multiple cards or specialty hardware | |||
Popular models for standalone use
Disclaimer: Download sizes are based on the base model from the model provider either via direct download or through a 3rd party hosting service. Where the model provider does not provide hardware requirements or recommendations, we are estimating the VRAM requirements and have not tested these specific models. Plugable does not endorse or support either the original base model or 3rd party models based on these or other models.
| Base Model Name (16-bit) | Base Model Download Size | Recommended GPU Memory Base Model | Recommended GPU Memory for Quantized Models | |
|---|---|---|---|---|
| 8-bit (INT8/Q8) | 4-bit (INT8/Q8) | |||
| gpt-oss-120b1 | 65.3 GB | 80 GB | 40 GB | 24 GB |
| gpt-oss-20b1 | 13.8 GB | 16 GB | 8 GB | 6 GB |
| DeepSeek-R1-Distill-Llama-8B2 | 16.07 GB | 48 GB | 24 GB | 12 GB |
| DeepSeek-R1-Distill-Qwen-7B2 | 15.23 GB | 32 GB | 16 GB | 8 GB |
| DeepSeek-R1-Distill-Qwen-1.5B2 | 3.55 GB | 12 GB | 6 GB | 4 GB |
| Qwen-72B3 | 144.18 GB | 160 GB | 160 GB | 80 GB |
| Qwen-14B3 | 28.32 GB | 32 GB | 20 GB | 16 GB |
| Qwen-7B3 | 13.39 GB | 24 GB | 20 GB | 16 GB |
| Qwen-1.8B3 | 3.67 GB | 6 GB | 4 GB | 4 GB |
| Gemma-3-27b-it4 | 54.35 GB | 80 GB | 40 GB | 24 GB |
| Gemma-3-12b-it4 | 24.37 GB | 32 GB | 16 GB | 8 GB |
| Gemma-3-4b-it4 | 8.6 GB | 12 GB | 6 GB | 4 GB |
| Gemma-3-1b-it4 | 2 GB | 6 GB | 4 GB | 4 GB |
| Llama 3.2 90B5 | Subscription Required | 200 GB | 160 GB | 40 GB |
| Llama 3.2 11B5 | Subscription Required | 24 GB | 12 GB | 8 GB |
| Llama 3.1 8B5 | Subscription Required | 20 GB | 12 GB | 8 GB |
| Ministral-3-14B-Reasoning-2512 (FP8)6 | 27.9 GB | 32 GB | 32 GB | 16 GB |
| Devstral-Small-2-24B-Instruct-2512 (FP8)6 | 25.75 GB | 32 GB | 32 GB | 16 GB |
| Ministral-3-14B-Instruct-2512 (FP8)6 | 15.7 GB | 24 GB | 24 GB | 12 GB |
| Ministral-3-8B-Instruct-2512 (FP8)6 | 10.4 GB | 12 GB | 12 GB | 8 GB |
| Ministral-3-3B-Instruct-2512 (FP8)6 | 4.67 GB | 8 GB | 8 GB | 6 GB |
| Color Key | ||||
| Mid-tier graphics cards | ||||
| High-end gaming cards | ||||
| "AI" accelerators | ||||
| Multiple cards or specialty hardware | ||||
Microsoft Foundry Local models compatible with Plugable Chat software
Microsoft Foundry Local models are specifically selected and quantized for local LLM use with readily available desktop graphics controllers.
Disclaimer: GPU memory recommendations are based on the memory used to load the model using both NVIDIA RTX 5080 16GB and Intel ARC B60 Pro 32GB graphics cards then rounding the used VRAM to the nearest common video card memory size leaving some room for model KV data.
| Model Name | Quantization | Download Size(Est.) | Recommended GPU Memory |
|---|---|---|---|
| Source: Foundry Local | |||
| deepseek-r1-distill-qwen-14b-generic-gpu:3 | Not Listed - Appears to be INT8/Q8 | 10.27 GB | 16 GB |
| qwen2.5-14b-instruct-generic-gpu:4 | Not Listed - Appears to be INT8/Q8 | 9.30 GB | 16 GB |
| qwen2.5-coder-14b-instruct-generic-gpu:4 | Not Listed - Appears to be INT8/Q8 | 8.79 GB | 12 GB |
| Phi-4-generic-gpu:1 | Not Listed - Appears to be INT8/Q8 | 8.37 GB | 12 GB |
| deepseek-r1-distill-qwen-7b-generic-gpu:3 | Not Listed - Appears to be INT8/Q8 | 5.58 GB | 8 GB |
| qwen2.5-7b-instruct-generic-gpu:4 | Not Listed - Appears to be INT8/Q8 | 5.20 GB | 8 GB |
| qwen2.5-coder-7b-instruct-generic-gpu:4 | Not Listed - Appears to be INT8/Q8 | 4.73 GB | 8 GB |
| Phi-4-mini-instruct-generic-gpu:5 | Not Listed - Appears to be INT8/Q8 | 3.72 GB | 6 GB |
| Phi-4-mini-reasoning-generic-gpu:3 | Not Listed - Appears to be INT8/Q8 | 3.15 GB | 6 GB |
| Phi-3.5-mini-instruct-generic-gpu:1 | Not Listed - Appears to be INT8/Q8 | 2.16 GB | 6 GB |
| Phi-3-mini-4k-instruct-generic-gpu:1 | Not Listed - Appears to be INT8/Q8 | 2.13 GB | 6 GB |
| Phi-3-mini-128k-instruct-generic-gpu:1 | Not Listed - Appears to be INT8/Q8 | 2.13 GB | 6 GB |
| qwen2.5-1.5b-instruct-generic-gpu:4 | Not Listed - Appears to be INT8/Q8 | 1.51 GB | 6 GB |
| DeepSeek-R1-Distill-Qwen-1.5B-trtrtx-gpu:1 | Not Listed - Appears to be INT8/Q8 | 1.43 GB | 6 GB |
| qwen2.5-coder-1.5b-instruct-generic-gpu:4 | Not Listed - Appears to be INT8/Q8 | 1.25 GB | 6 GB |
| qwen2.5-0.5b-instruct-generic-gpu:4 | Not Listed - Appears to be INT8/Q8 | 0.68 GB | 6 GB |
| Color Key | |||
| Mid-tier graphics cards | |||
| High-end gaming cards | |||
| "AI" accelerators | |||
| Multiple cards or specialty hardware | |||
